Daniel 2019/01/04 字数:12860
1 前言
-
分布式事务这个命题比较大,落地场景也是非常复杂的,原本想做一些演示,但苦于没有时间,退一步想在队列、消息一致性、线程同步等周边命题上做一些简单演示,也同样没有时间准备,暂立FLAG吧,具备完整方案的分布式微服务我们肯定会要上的;
-
所以本篇大多是一些网络摘取,然后对相关知识点进行了排序整理,去掉一些详细陈述,保留一些我认为是要点的东西,同时给出了大量的链接辅助大家去扩展相关的知识;
-
有背景色,是我的表述,略显粗俗也并不一定严谨,望谨慎分辨
2 大纲
首先,介绍事务,特别注意一致性、隔离性;
其次,介绍万物归一的数据库事务;
再,介绍分布式事务的概念;举个通俗、较易理解,但不一定够工程化的栗子来引申解决方案;
后,简易介绍更多分布式解决方案;回顾分布式解决方案的理论基础;
再再,泛事物的介绍,比如感觉上很有一致性和隔离性的队列,也有锁的线程同步,多个消息队列居然也讲究并行和依赖,最终如何达成一致;
再后,hibernate的事务、redis的锁、spring的事务,以及一些使用上的小情况;
3 事务的定义
由一组操作构成,要么全部正确执行,要么因任意一个错误而回滚,全部不执行,[引1]
4 特性
-
原子性(Atomicity)(
形态) 事务里的操作是一个整体,全进或全退,[引2] -
一致性(Consistency)(
条件) 执行前和后环境的约束条件不变,约束条件发生变化将导致事件不可执行。数据库会利用锁的机制阻塞其它事务执行,[引3] -
隔离性(Isolation)(
过程) 事务之间相互独立。比如修改的相互隔离,事务查看数据时,所处状态要么就是另一并发事务修改它之前,要么就是修改它之后,[引2] 。如果不独立相互依赖就麻烦了,事务与事务之间缺乏恢复的沟通机制 -
持久性(Durability)(
结果) 提交后,影响是持久的,能被或已被滚雪球
问题:
我们说的这些事务到底是数据库事务,还是别的什么事务?比如spring事务
回答:
本质上是一个概念,spring的事务是对数据库事务的封装,帮助开启回滚和关闭,并有一定的传播机制和隔离级别,没有数据库的支持spring的事务不会起作用,[引4]
spring更多站在应用层的角度,避免了繁琐的操作指令
5 常规的数据库事务的隔离级别选择
四种情况:
Read uncommitted——写事务排斥其它写,但可读。后果:脏读(读到未提交的),不可重复读(两次读到不同的已提交的数据)
Read committed——写事务排斥其它读写,但是读事务允许其它读写(注意先后)。后果:不可重复读
Repeatable read——写事务排斥其它读写,但读事务允许其它读不允许其它写
Serializable——所有串行执行,并发效率低
一般,优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读和第二类丢失更新这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
6 什么是分布式事务?
单体程序,在spring框架下,只需要将多个表的操作放到一个方法里,加上@Transactional注解。微服务架构中,多个表的首先可能不在同一个数据源中,其次多个操作也分布在不同的程序上(即不同的JVM进程上)
7 不一定够工程化的栗子
关于这个示例,作者自称不走两阶段、三阶段提交协议,而是采用本地事务以及消息队列来实现。[引5]
业务流程:
(1)注册成功,保存用户信息
(2)给新注册的用户发放一张代金券,用于鼓励用户消费
7.1 整体方案
单体程序的话,在一个事务中,给两个表分别插入数据即可。而分布式事务如何解决?
在用户注册时创建一个事件,成功后用户服务将这个事件发送到消息队列,代金券服务监听用户服务的事件,收到事件,即在自己的库中创建一张代金券
7.2 原子性保障
原子性如何保障?主要指如何保证A服务成功发送消息以及B服务成功获取到消息
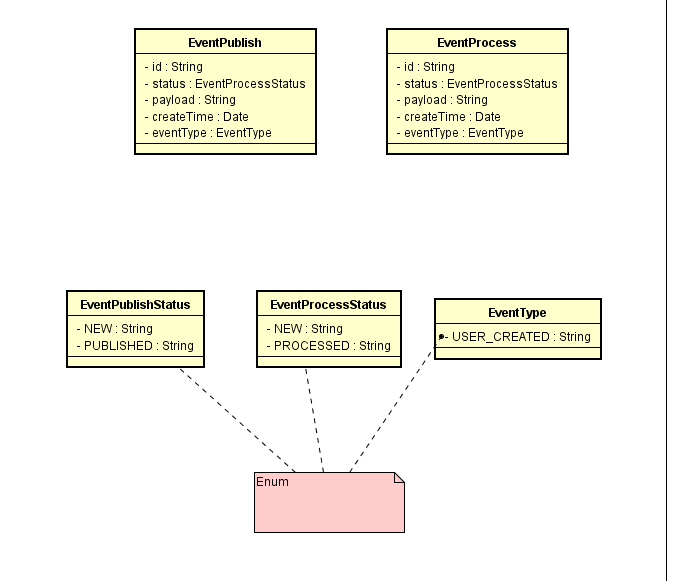
通过事件表EventPublish:
-
id: 每个事件在创建的时候都会生成一个全局唯一ID,例如UUID。
-
status: 事件状态,枚举类型,现在只有两个状态:待发布(NEW),已发布(PUBLISHED)。
-
payload: 事件内容,这里我们会将事件内容转成json存到这个字段里。
-
eventType: 事件类型,枚举类型,每个事件都会有一个类型,比如我们之前提到的创建用户USER_CREATED就是一个事件类型。
EventProcess是用来记录待处理的事件,字段与EventPublish基本相同。
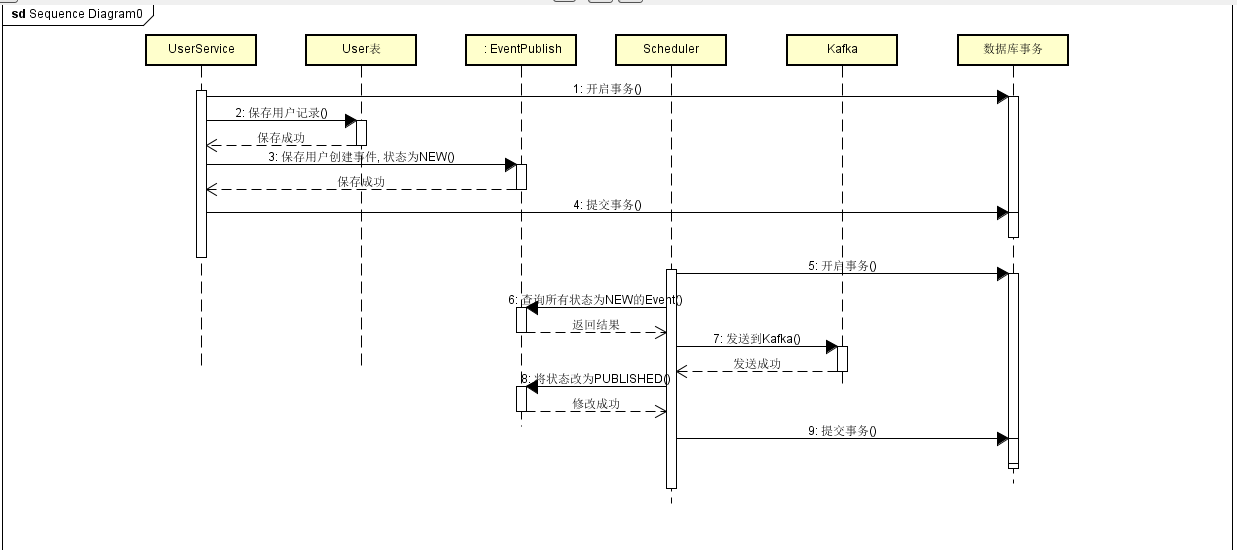
下面是用户服务发布用户创建事件的顺序:
代金券服务处理事件的顺序:
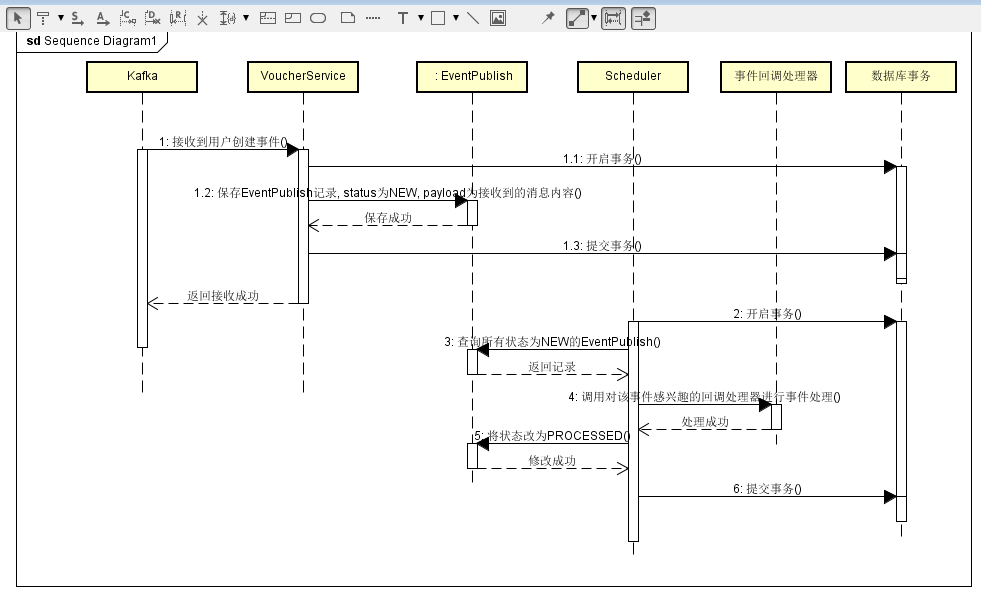
为什么创建事件和发布事件,接收事件和处理事件拆分呢?
理论上应该是可以的,但消息通道运行在另一个平行空间,任务是异步处理的方式,如果将业务事务包含发布事件,从形态上讲就造成了对消息通道的强依赖
7.3 方案优缺点
优点:
(1)异步无等待,有较高的吞吐量,容错性较好
(2)A服务不要求B服务同时在线
缺点:
(1)开发调试比较复杂
(2)对中间状态的容忍度问题,比如代金券没有及时到位,这个就是牺牲强一致性换高可用性了,只需要保持最终的一致性,但是在一些强一致性要求高的强景是不适合的,比如金融业,[引6]
(3)事件数据库操作会带来额外的压力
(4)B服务因不可抗拒的原因无法执行,A服务的事务如何能及时回撤?
(5)对应用的侵入性比较高,如果是后期考虑则需要进行大量的业务改造,[引7]
8 为什么要分布式?CAP理论
(1)C:Consistency 一致性
同一数据的多个副本是否实时相同。
(2)A:Availability 可用性
可用性:一定时间内 & 系统返回一个明确的结果 则称为该系统可用。
(3)P:Partition tolerance 分区容错性
将同一服务分布在多个系统中,从而保证某一个系统宕机,仍然有其他系统提供相同的服务。
CAP理论总结说:在一个分布式系统中,最多只能满足C、A、P中的两个需求。怎么理解这个事,[引8]
为什么不能完全保证这个三点了,个人觉得主要是因为:
(1)一旦进行分区了,就说明了必须节点之间必须进行通信P,涉及到通信,就无法确保在有限的时间内!A完成指定的行文。`这个理解比较浅层次的,分区并不意味着不能在一定时间内完成`
(2)如果要求两个操作之间要完整的进行,因为涉及到通信P,肯定存在某一个时刻只完成一部分的业务操作,在通信完成的这一段时间内A,数据就是不一致性的!C。
(3)如果要求保证一致性C,那么就必须在通信P完成这一段时间内保护数据,使得任何访问这些数据的操作不可用!A。
我把他的文字描述找字母来转义了,出现的组合有AP\CP,AC组合没有提,当然是没问题的,就是我们常做的单体事务,数据放在单库中
根据这个理论,分布式业务系统取向:AP,一是提升业务处理量,二是根本性的分区容错。一个新的BASE理论,BA:Basic Available 基本可用S:Soft State:柔性状态,不需要实时一致,E:Eventual Consisstency:最终一致性。与事务的ACID对比看看?
9 分布式的架构——微服务 VS 分布式事务
[引7],微服务将复杂的单体应用拆分为若干个功能简单、松耦合的服务,这样可以降低开发难度、增强扩展性、便于敏捷开发。但存在一些新问题:
-
进程间的通讯机制和故障处理措施变的更加复杂(RPC框架来解决,比如dubbo、springcloud);
-
分布式事务问题非常突出(本篇主题);
-
数量众多,其测试、部署、监控等都变的更加困难(docker、devops以及公有云paas平台自动化运维工具解决这个问题)。
10 理论基础——分布式事务常见一致性模型
![Image.png]](https://yidu.seaeverit.com/cslib_image/roadl/712295cb44bfe134db81559460dcbd82.png)
{kind=link}
-
两阶段、三阶段:操作的是事务性资源——数据库、消息队列、EJB组件,关于更多的相关介绍参考:[引1]
-
sagas长事务:定义一个事务集,包括子事务及其对应的补偿子事务
-
补偿:sagas是一种复杂的补偿,简单场景下的补偿介绍可参考这里,[引9]
-
可靠事件:上述例子就是这个模式
-
TCC:是优化的(Try-Confirm-Cancel)补偿模式,参考上文
11 更多分布式事务解决方案
11.1 GTS
GTS创始人的介绍,解决了事务ACID特性与AP(指标上是高性能、高可用、低侵入)不可兼得的问题(这样看来它宣称是颠覆了CAP的不可能原理),使用非常简单,业务代码加@TxcTransaction即可:[引7]
示例代码:
//订单服务,使用注解开启事务,
@TxcTransaction(timeout = 1000 * 10)
public void Bussiness(OrderService orderService, StockService stockService, String userId) {
//获取事务上下文
String xid = TxcContext.getCurrentXid();
//通过RpcContext将xid传到一个服务端
RpcContext.getContext().setAttachment("xid", xid);
//执行自己的业务逻辑
int productId = new Random().nextInt(100);
int productNum = new Random().nextInt(100);
OrderDO orderDO = new OrderDO(userId, productId, productNum, new Timestamp(new Date().getTime()));
orderService.createOrder(orderDO);
//RpcContext通过隐藏参数将GTS的事务xid传到另一个服务端
RpcContext.getContext().setAttachment("xid",xid);
stockService.updateStock(orderDO);
}
//服务提供者
public int updateStock(OrderDO orderDO) {
//获取全局事务ID,并绑定到上下文
String xid = RpcContext.getContext().getAttachment("xid");
TxcContext.bind(xid,null);
//执行自己的业务逻辑
int ret = jdbcTemplate.update("update stock set amount = amount - ? where product_id = ?",new Object[]{orderDO.getNumber(), orderDO.getProductId()});
TxcContext.unbind();
return ret;
}
GTS作者在微博上对这个探索文章进行了@ [引11],还有其它粉丝:
- 下面有一个疑蹭热点的留言:
GTS确实很赞,其核心原理是 补偿。但这个补偿做得很屌,补偿操作由框架自动生成,无需业务干预,框架会记录修改前的记录值到上面的txc_undo_log里,若需要回滚,则拿出undo_log的记录覆盖回原有记录
同时这里存在一个事务隔离级别的问题,GTS的做法是默认脏读,那么就可以直接拿数据库记录展示(但个人觉得应该可以不做脏读,直接拿undo_log里的记录做mvcc,只要undo_log记录不大,都可以加载到内存里)。
还有另外一个问题是如何禁止其他事务对进行中的全局事务记录的更新,GTS的做法是需要接管APP中的数据源,这样就可以解析控制业务要执行的SQL,对于update操作(或者select for update),予以禁止或等待。
不过整体的做法相当于魔改数据库,将数据库的部分功能拉到了业务APP里进行,并修改了默认隔离级别(脏读,如果业务有用数据库记录乐观锁来控制并发的话,将会失效),还有就是,不通过GTS的定制数据源访问会访问修改到未提交数据
如果作者能自行介绍下GTS的优缺点会更方便,更权威,毕竟大家做选型肯定要了解原理才敢用
然后贴了一个自己写的分布式事务框架:[引12],这里还有一篇他对各分布式事务框架的偏见:[引13]
- GTS是商业工具并未开源,这个小伙逆向jar包,进行了GTS开发路线的探索:[引14]
他的猜想:
所以我的大致猜想是这样的,如果不对欢迎拍砖
1. TXC 是基于 rocketmq ,Netty 来实现的。
2. 实现了一个 以rocketmq 和 操作库 的 tx_undo_log 做日志存储 ,Netty RPC 做事务控制的二阶段提交协议。
3. 在事务提交阶段,会同时开启一个事务,锁住 分布式事务的参与记录,等待事务合并后释放。或者有节点提交错误时回滚。
一个事务的处理流程我认为可能是这样的
1. 启动之后 启动RPC连接上事务控制服务
2. 包装了 DataSource ,和 jdbc 的 Connection ,在进行 DML 操作之前,先使用 解析到对应表的 ,使用 SELECT xxx from xx for update 语句 构造 undo 语句。
操作完了后,发送一个消息,通知事务控制服务,可以本事务可以提交了。
3. 判断自己外部 是否还有事务(即是自己是不是最外层事务)。如果自己不是最外层事务,则返回(不阻塞线程), 如果自己是最外层事务,则 等待事务 提交(当前线程阻塞).
4. (另外的线程)Rpc 接受到 事务控制器 提交事务命令后。获取合并事务。如果成功(柱塞住参与事务的表记录),回复成功消息,失败回复失败消息(回滚,不再锁住表记录)。
5. 根据事务提交情况,控制器会 下发,完成事务,或者回滚事务的命令,由RPC线程处理, 如果成功则释放,锁住的表记录,事务完成, 最外层业务线程的阻塞返回结束,
如果失败,则执行 uodo 日志里面的sql ,回滚操作,释放表记录, 最外层业务线程阻塞返回抛出 事务异常。
现在没想明白的问题:
1. 在事务提交阶段,提交后表记录,的锁已经释放,怎么样才能保证该行数据能被后续的锁操作锁住,业务在大量事务操作的时候,可能记录先被其他的事务抢到了。
我把我的猜想跟我同事说了后他觉得这个 做法有点像
ebay经典的BASE (basically available, soft state, eventually consistent)方案
希望各位大神能提出看法
12 再再,泛事物的介绍,比如感觉上很有一致性和隔离性的队列,也有锁的线程同步,多个消息队列的并行和依赖,最终如何达成一致
12.1 消息队列
[引15] 问题1:
A评论B后,会给B发异步通知,然后A删除评论时,会异步删除这个通知。问题:消息队列中有两个消息:发通知和删除通知,由于有并发(多个进程处理消息队列中的消息),可能先执行的是删除通知,然后才执行的发通知,这导致的结果是通知没有被删除。
探讨——:消息队列并行且依赖,如何做到。(原本想做个程序演示)
[引8] 问题2:
假设有一个主数据中心在北京M,然后有成都A,上海B两个地方数据中心,现在的问题是,假设成都上海各自的数据中心有记录变更,需要先同步到主数据中心,主数据中心更新完成之后,在把最新的数据分发到上海,成都的地方数据中心A,地方数据中心更新数据,保持和主数据中心一致性(数据库结构完全一致)。数据更新的消息是通过一台中心的MQ进行转发。.
先把问题简单化处理,假设A增加一条记录Message_A,发送到M,B增加一条记录 MESSAGE_B发送到M,都是通过MQ服务器进行转发,那么M系统接收到条消息,增加两条数据,那么M在把增加的消息群发给A,B,A和B找到自己缺失的数据,更新数据库。这样就完成了一个数据的同步。
从正常情况下来看,都没有问题,逻辑完全合理,但是请考虑以下三个问题
1 如何保证A->M的消息,M一定接收到了,同样,如何保证M->A的消息,M一定接收到了
2 如果数据需要一致性更新,比如A发送了三条消息给M,M要么全部保存,要么全部不保存,不能够只保存其中的几条记录。我们假设更新的数据是一条条发送的。
3 假设同时A发送了多条更新请求,如何保证顺序性要求?
这两个问题就是分布式环境下数据一致性的问题
探讨——分布式消息最终一致,这个思考是非常零散的,举了不少的应用场景,知识涉及到前文提到的一些。
12.2 线程同步
在氢读项目中有这样的应用场景,比如,访问接口生成二维码,有单独的线程1来处理这次访问,然后需要线程2发一个消息给mqtt服务器,向订阅者线程3请求获得二维码的内容,线程2从mqtt服务器获得内容后,将内容返回到线程1接口,将二维码内容生成图片并返回给访问者。
粗斜体部分描述的即是一段同步等待的过程,关于同步方法见
com.xxx.xxx.service.mqtt.SimuTerminalMqttMessageConsumer#startCardReg,
由于是模拟功能,未考虑到数据的窜用问题
13 再后,hibernate的事务、redis的锁、spring的事务,以及一些使用上的小情况
13.1 hibernate的锁
大家应该都写过这一块的代码,hibernate的批量插入和更新,含事物概念,但一个业务操作被拆成多个事务:[引16]
(原本想扩散这一块,做个DMEO,特别对标spring data JPA)
hibernate对事务锁的使用,对标数据库事务的特性,几把锁的特点:[引17]
(原本计划做一个演示,也非常有意义。这个大家估计接触的不多,特别是现在spring boot这样一个开发框架下,很多接近底层理论的应用也逐渐要失去,在业务开发上来讲是好事,但在技术体系的建立上是坏消息)
redis也有锁的,这个大家平时用的也很少 [引18]
13.2 spring data jpa的事务
spring data jpa相对于hibernate,对数据层的开发就更加简化了。自定义的base repository也方便做一些表的基础属性的统一处理。
jpa的更新操作需要注解为事务; 注解不要写在接口方法上; 注解可以定义到repository实现类的类上,或方法上,方法上优先;提倡注解定义到service的方法上,优先在调用者上注解。 这些内容是在一些书上难以找到的
service层声明事务注意事项,这里面也提到了一些关于注解的使用注意事项,比如同一个类里两个方法互调则注解无效,貌似@Cacheable等注解也是这个情况:[引19]
spring的事务声明方式,以及注解的使用注意事项:[引20] [引21] [引22]
14 其它脑洞,不做分布式事务行不行?
了解一下幂等性: [引23],根据幂等性,用消息队列和消息应用状态表一起来解决问题,实现分布式BASE场景:[引24]
附,参考资料
[引1] 阿里员工,其分享了一些面试知识,对基础技术时常总结,这篇是对分布式的一些事务理论进行了一些讲解
[引2] 百度知道的回答,对事务的ACID进行了一些通俗叙述
[引3] 对ACID和一致性的基本概念有一些阐述
[引4] 对spring事务的本质有一些简单描述
[引5] 讲述利用事件加消息通道解决分布式事务的问题
[引6] 分布式模型的相关介绍
[引7] GTS作者的一篇介绍文章,里面有一些关于各种解决方案的描述
[引8] 一些分布式一致性的场景,比较散乱
[引9] 重点讲了一下类于ebay的补偿模式以及TCC,这篇具有一定的网络效应
[引10] 网易云官方号对分布式的一些理论阐述
[引11] 一个极客对GTS的理解,GTS作者有推荐这篇文章
[引12] github上一个分布式事务框架,看起来不错
[引13] 上一个链接的事务框架的作者对其它事务框架的偏见
[引14] 对GTS的逆向分析,大量的图
[引15] 消息队列的同步,比较烧脑
[引16] hibernate的批量事务
[引17] 数据库的一些事务和锁以及框架对其的引申
[引18] 浅谈redis的锁
[引19] spring service层对事务注解引用的注意事项
[引20] spring配置事务的几种方式
[引21] spring配置事务的几种方式,还有一张示意图
[引22] spring两个事务注解的相互影响问题
[引23] 幂等性简介
[引24] 不用分布式事务来搞定分布式业务